Les données de santé : données ou construites ?
Publié par Lou Benezit, le 14 octobre 2025 600
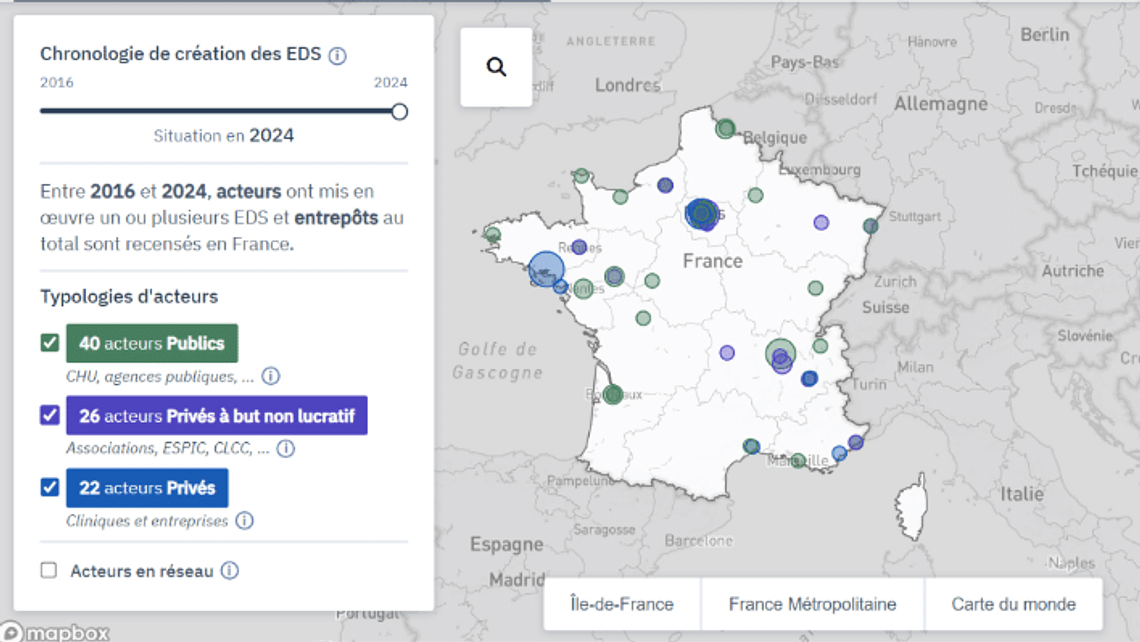
Médecine prédictive et personnalisée, intelligence artificielle, patients virtuels : autant de promesses autour d’une “médecine de demain” qui façonnent notre imaginaire dans lequel les données seraient abondantes, disponibles et prêtes à l’emploi. Pourtant, les données que génèrent les patients, les soignants, les dispositifs médicaux ne sont pas autonomes et le processus n’est ni évident, ni instantané. Elles sont au contraire produites, déplacées, stockées, travaillées, nettoyées et sont ainsi traversées par des questions d’ordre éthique, professionnel, clinique, juridique, technique, politique et encore économique. Depuis 7 ans, de nombreux entrepôts de données (EDS) ont été autorisés par la CNIL et déployés dans toute la France.
Cartographie des entrepôts de données de santé français.

Source : Commission nationale de l’informatique et des libertés.
Les entrepôts de données de santé sont souvent abordés par le prisme technique, ce qui contribue à invisibiliser le travail nécessaire à la création, au traitement et à la réutilisation de ces données. Les controverses autour du choix du Cloud Microsoft comme prestataire du Health Data Hub (plateforme nationale des données de santé) ont occulté les difficultés que présente la constitution d’un réseau d’acteurs hospitaliers, la standardisation des pratiques et des formats utilisés, pour pouvoir alimenter une plateforme nationale avec des données hétérogènes. Ainsi, cet article présente une description synthétique du chemin des données de santé hospitalières. Ce travail, qui s’appuie sur des observations menées au sein d’un CHU du grand Ouest, ainsi que des entretiens dans différents CHU français, s’inscrit dans le cadre d’une thèse de sociologie cofinancée par la région des Pays de la Loire et l’ISEN YNCREA OUEST.
Un hôpital comme l’AP-HP réalise environ 8 millions de prises en charge par an1. Chacune d’elles donne lieu à la création d’un certain nombre de documents. Une question importante est de savoir lesquels d’entre eux (prescriptions, diagnostics, compte-rendu, résultats d’analyses biologiques, etc) seront entreposés à des fins de recherches. L’usage premier de ces données se fait, en effet, dans le cadre de la prise en charge du patient. Elles sont le fruit de l’interaction entre le patient et les équipes hospitalières (admissions, médecins, paramédicaux, étudiants, etc). Ce contexte est variable en fonction des individus, des services de santé, des établissements et des logiciels utilisés. Les données ne sont donc ni exhaustives, ni neutres et ne constituent qu’une représentation limitée d’une réalité. De plus, les établissements utilisent des systèmes d’information qui ne sont pas systématiquement interopérables puisque chaque CHU est garant de la sécurité des données construites localement. Par ailleurs, les éditeurs de logiciels hospitaliers ne sont pas toujours à jour sur l’intégration de nouvelles techniques ou fonctionnalités, souvent pour des raisons de rentabilité. Cela oblige les services hospitaliers à improviser des solutions pour contourner les limites des systèmes.
Le dossier patient informatisé, dans lequel sont inscrites ces données, fait partie du système d’information hospitalier. Ce système d’information réunit l’ensemble des logiciels de l’hôpital (soins, admissions, RH). Cette interopérabilité se travaille et cette tâche se fait en collaboration avec les éditeurs de la plateforme et les équipes de la direction des services numériques de l’hôpital. Avant l’extraction – la transformation – les données vont être sélectionnées en fonction de certains critères. On relie d’abord le flux de patients (logiciel utilisé pour les admissions) puis le dossier patient informatisé. Ce travail est renouvelé lors de mises à jour régulières ou encore lors de changements de serveur, ce qui nécessite donc un long travail de vérification et de correction. Prenons un exemple : lors d’une migration, tous les caractères typographiques [é] enregistrés dans des comptes rendus de soin sont modifiés. Ceci altère automatiquement tous les résultats des requêtes sur l’entrepôt de données, ce qui entraîne d’importants biais méthodologiques. Ainsi, l’épilepsie, l’énurésie ou l’épisode dépressif majeur, risquent de ne pas apparaitre comme résultat de la recherche si la demande est bien orthographiée.
L'enquête sur le circuit des données a été réalisée dans un hôpital qui fournit aussi bien les données que le service associé. Ainsi, une équipe composée d’informaticiens, de statisticiens, d’épidémiologistes, de médecins, d’ingénieurs, de data scientist et d’un chef de projet, s’occupe quotidiennement du maintien et de l’exploitation de cet entrepôt de données de santé. Cette unité reçoit sur une plateforme dédiée, les demandes des chercheurs (médecins, internes, attachés de recherches cliniques ou industriels). Le projet de recherche est discuté en équipe (faisabilité, dimension éthique, cadre légal, question scientifique, etc.), affiné si besoin et les variables à rechercher sont définies. Ces tâches nécessitent une grande capacité d’adaptation et de traduction pour coopérer avec de multiples porteurs de projets aux profils variés. Cela suppose d’abord une connaissance approfondie du contexte d’inscription des données. En effet, les médecins utilisent des codes appelés CIM-10 pour catégoriser les diagnostics et soins effectués afin de les transmettre pour remboursement à la Sécurité sociale. Ce codage est aussi utilisé à des fins secondaires pour la recherche. Toutefois, il ne reflète pas toujours une réalité strictement clinique : certains choix de codage relèvent aussi d’une logique économique, puisque certains codes sont plus rémunérateurs que d’autres.
Le travail des données suppose ensuite une maîtrise des méthodes scientifiques et méthodes de mise en forme par les langages de programmation informatique. A cela s’ajoute la nécessité de connaître précisément le cadre légal de protection des données (RGPD).
Les données nécessaires aux projets de recherche sont ensuite regroupées par les équipes pour créer un datamart sur une plateforme de requêtage, qui elle aussi demande à être développée. Une fois mis à disposition, le chercheur peut accéder à son espace professionnel sécurisé. Il procède ensuite à un second nettoyage de sa base de données pour voir si cela correspond aux variables qui lui sont nécessaires. C’est seulement lorsque ces données sont collectées, traitées, analysées qu’elles deviennent une source d’information : une donnée scientifique. Le chercheur peut alors ou non, communiquer ses résultats à l’ensemble de la communauté scientifique.
Le travail des données, souvent invisibilisé, est pourtant essentiel dès leur création. Les données ne circulent pas de façon aléatoire ou magique. Elles suivent au contraire un parcours précis, marqué par l’intervention de différents profils d’experts, de collaborations, de règlementations, de normes scientifiques et de techniques. Ainsi, selon certains professionnels de la recherche médicale, les entrepôts de données de santé permettraient à la fois de mener à bien une recherche à partir de bases de données plus étendues que leur service, de veiller à la bonne application du RGPD (règlement général à la protection des données) et de répondre aux stratégies de rayonnement scientifiques et RH des hôpitaux.
La majorité des débats à ce sujet, portent sur les enjeux éthiques de la réutilisation des données personnelles. Ces questions ont été abondamment discutées par la CNIL et les autorités de santé. Un enjeu plus complexe est celui du périmètre de partage des données. Autant la recherche de preuve scientifique peut pousser à passer à des échelles de stockage et de traitements très importantes, autant la nécessité stratégique et politique de maitriser les opérations de traitements suscite la prudence. À l’aune de la construction de l’Espace européen des données de santé, se pose la question des effets d’une nouvelle échelle, qui se superpose aux niveaux locaux, interrégionaux et nationaux, sur ces travailleurs discrets de la donnée. Comment cette expertise, inhérente au contexte de la donnée, s’ajustera-t-elle entre centralisation et décentralisation ? Enfin, face à un contexte d’inscription aussi hétérogène, où se situera le juste équilibre entre particularités locales et standardisation ? Autant de questions que la sociologie a pour but de soulever et d’éclairer en analysant les pratiques locales et en les confrontant aux enjeux nationaux.